4. Conectores#
Las bases de datos relacionales son uno de los soportes más utilizados para el almacenamiento organizado de información. Su problema, al ser accedidas mediante aplicaciones, es que basan su estructura en el modelo relacional, que no es el modelo que usan los lenguajes de programación para manejar datos. En concreto, los más habituales, los lenguajes de POO manejan los datos haciendo uso del modelo de objetos, por lo que existe una discrepancia entre el modo en que tratan los datos los SGBD relacionales y el modo en que los tratan los lenguajes. Para afrontarlo, los lenguajes utilizan dos estrategias distintas:
El uso de conectores, en que el acceso a la base de datos se realiza mediante sentencias SQL y la traducción del modelo relacional al modelo de objetos corre a cargo del programador.
El uso de herramientas ORM en que la traducción entre ambos modelos corre a cargo de la propia herramienta siguiendo las orientaciones del programador.
Podemos entender mejor estas dos estrategias si las comparamos con estrategias ya vistas anteriormente para acceder a otros soportes de datos:
La primera estrategia es la misma que sigue la librería commons-csv para leer y escribir CSV.
La segunda estrategia es la que sigue la librería Jackson para leer y escribir distintos formatos.
Ambas estrategias tienen sus ventajas e inconvenientes:
- Ventajas de los conectores
Mayor control sobre las operaciones, al definirse manualmente, lo que permite ajustar más la solución al problema concreto o utilizar características avanzadas de SQL.
Al haber menos abstracción, suele ser una estrategia de mayor rendimiento, siempre, claro está, que el programador sea hábil. Si no lo es, puede resultar todo lo contrario.
Es una solución más fácilmente depurable.
Son más sencillos de aprender que un ORM, aunque luego sea más laborioso escribir con ellos la aplicación.
Los conectores suelen formar parte de las librerías básicas del lenguaje, por lo que no necesitaremos usar una librería de terceros (la librería ORM) ni tendremos que reescribir el código si decidimos cambiar a un ORM distinto.
- Ventajas de las herramientas ORM
Evitan al programador que tenga que codificar la traducción entre el modelo tradicional y el modelo de datos del lenguaje de programación, por lo que son herramientas más productivas.
El programador trata los datos directamente como objetos, lo que hace el código más sencillo y manipulable.
Generalmente, cambiar de SGBD es trivial, puesto que la herramienta nos abstrae de sus particularidades. Su uso, por tanto, nos independiza de cuál sea el SGBD que gestione los datos frente a los conectores que usan sentencias SQL, generalmente dependientes de cuál es el SGBD. En contrapartida, puede resultar muy trabajoso cambiar de ORM[1]. Con conectores, en cambio, hay que usar sentencias SQL y estas dependen del SGBD por lo que un cambio en éste obligará a repasar el código.
En esta unidad abordaremos la primera estrategia y dejaremos la segunda para la unidad siguiente.
Java proporciona para el acceso a bases de datos relacionales una API en su JDK llamada JDBC, lo que posibilita que el acceso sea idéntico sea cual sea el SGBD que se decida utilizar. Esto no significa que el código sea independiente del motor subyacente, puesto que cada motor tiene sus particularidades que extienden el SQL estándar y esta estrategia, al estar basada en la construcción de sentencias SQL, nos obliga a utilizarlas. Lo que en realidad es común son los métodos que proporciona Java para ordenar la ejecución de las sentencias al motor de la base de datos. Además de la API, necesitaremos para cada SGBD un driver basado en la API que posibilite la conexión. Este driver sí que será una librería de terceros que deberemos incluir en nuestro proyecto.
SGBD de referencia
Nota
Procuraremos escribir sentencias SQL que cumplan el estándar para que el código sea lo más portable posible.
Para aprender y practicar el acceso con conectores, podemos escoger cualquier SGBD. Ahora bien, lo habitual es que los SGBD tengan una arquitectura cliente-servidor para propociar el acceso remoto y concurrente a los datos. Esta arquitectura está bien; pero, como nuestra intención es aprender a programar con bases de datos relacionales y no tanto crear programas reales para producción, montar una arquitectura de este tipo puede desviar esfuerzos del propósito principal. Por ese motivo (y con independencia de que se propongan ejercicios adicionales en que se usen SGBD como MariaDB o Oracle), centraremos nuestra atención en dos SGBD que posibilitan el manejo de una base de datos relacional sin necesidad de configurar un servidor:
SQLite, que es un SGBD escrito en C, cuyas bases de datos son simples archivos y se usa ampliamente en aplicaciones escritas en diversos lenguajes que organizan sus datos con una base de datos exclusiva sobre la que no concurren otros procesos.
H2, que es un SGBD programado en Java que ocupa poco espacio y permite además de modo standalone, practicar una arquitectura cliente-servidor.
En cualquier caso, las explicaciones serán totalmente válidas para cualquier SGBD relacional.
Nota
La librería sqlite-jdbc incluye un motor de SQLite para facilitar su uso, pero es conveniente que tengamos instalado nosotros mismos el motor en el sistema operativo, por si queremos hacer pruebas:
Las distribuciones de Linux suelen incluir un paquete, por lo que su instalación es trivial.
Para sistemas Windows la página oficial ofrece binarios precompilados, pero no un instalador automático. La instalación, no obstante, es sencilla:
Guardar los archivos suministrados dentro del zip en un lugar adecuado (p.ej.
C:\Program Files\SQLite).Añadir el directorio al PATH del sistema.
Ejercicio ilustrativo
Tomaremos como base un problema muy sencillo en el que simplemente existen centros y estudiantes matriculados en ellos. Podemos representarlo gráficamente con el siguiente diagrama E/R:
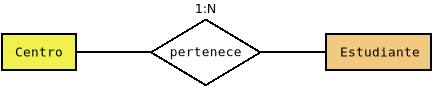
Podemos traducir el anterior esquema al modelo relacional así:
Centro(*id*, nombre, titularidad)
Estudiante(*id*, nombre, nacimiento, _centro_)
el cual en SQL se define así:
CREATE TABLE Centro (
id INTEGER /* GENERATED BY DEFAULT AS IDENTITY */ PRIMARY KEY,
nombre VARCHAR(200) NOT NULL,
titularidad CHAR(7) CHECK (titularidad IN ('público', 'privado'))
);
CREATE TABLE Estudiante (
id INTEGER /* GENERATED BY DEFAULT AS IDENTITY */ PRIMARY KEY,
nombre VARCHAR(250) NOT NULL,
nacimiento DATE NOT NULL,
centro INTEGER,
CONSTRAINT fk_est_cen FOREIGN KEY(centro) REFERENCES Centro(id)
ON DELETE SET NULL
ON UPDATE CASCADE
);
Consejo
Mucho de lo propuesto en esta unidad está incluido en un repositorio de Github llamado sqlutils listo para su uso[2]:
<!-- En pom.xml -->
<repositories>
<repository>
<id>jitpack.io</id>
<url>https://jitpack.io</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.github.sio2sio2.sqlutils</groupId>
<artifactId>sqlutils-core</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>
Contenidos
Notas al pie