4. Transformación de datos#
Habitualmente de los datos almacenados en documentos sólo requerimos obtener una parte de ellos u obtenerlos todos, pero en un formato distinto. En esta unidad trataremos los lenguajes que permiten la conversión entre distintos documentos de datos, en particular entre distintos documentos XML, para lo cual requeriremos las técnicas de Consulta de datos aprendidas en la unidad anterior.
Nota
Complementaria a esta tarea, se encuentra la de la extracción de datos almacenados en bases de datos, que requiere consultar (Consulta de datos) y generar una salida (Transformación de datos). Esto, sin embargo, se reserva para la unidad siguiente dedicada al almacenamiento.
Centraremos el estudio en el XML, para lo cual existen dos grandes lenguajes:
XQuery, que permite conversiones sencillas y al que dedicaremos el resto de la unidad.
XSLT, que permite conversiones mucho más complejas y que, por ello, requiere un estudio más detallado y extenso.
4.1. XQuery#
XQuery es un lenguaje de consulta que permite obtener una salida XML
(aunque no necesariamente) a partir de una fuente XML (aunque, de nuevo, no
necesariamente). Para ello, usa XPath como herramienta de selección la
información y una estructura prototípica llamada FLWOR por las cinco
cláusulas con las que se construye originariamente[1]. Cumple en el mundo
XML exactamente la misma función que las cláusulas SELECT en el mundo
SQL.
En cualquier caso, aunque lo que caracteriza a XQuery es la estructura
FLWOR, esta no es obligatoria, y una consulta XQuery puede crearse
únicamente con el contenido del RETURN del FLWOR (sin
expresar el propio return). Como este contenido puede ser cualquier
expresión XPath válida, resulta que XQuery es un superconjunto de XPath, o
lo que es lo mismo, toda expresión XPath es una consulta XQuery válida.
Tres son las versiones que ha tenido este lenguaje:
- Versión 1
Desarrollada desde los comienzos de XPath en 1999, se publicó definitivamente en 2007, con lo que hace uso de XPath 2.0.
- Versión 3
Publicada en 2014, con lo que incorpora XPath 3.0, añade como novedad fundamental convertir a las funciones en ciudadanas de primera clase.
- Versión 3.1
Es el último estándar aparecido en 2017, con lo que incorpora XPath 3.1.
Nota
No existe versión 2. La relación entre XQuery y XPath es tan íntima que se prefirió alinear las versiones de XQuery con las de XPath.
Una característica importante de XQuery es que, a diferencia de XSLT, no tiene sintaxis XML, aunque existe una versión normativa (XQueryX) que la implementa.
Prudencia
Téngase presente que XQuery comparte el modelo de datos de
XPath y, por tanto, todo lo indicado respecto a los tipos en las
expresiones es también aplicable. Por ejemplo, si no se ha validado el
documento, los datos serán xs:untypedAtomic, que se comportan más o menos
como cadenas, nunca como números.
Como complemento a estos apuntes, puede consultar, además de las propias especificaciones, estas dos extensísimas fuentes:
Wiki sobre XQuery, con abundantes ejemplos sobre cómo resolver muchos problemas concretos.
Novedades de XQuery 3, que es el índice de un curso sobre los añadidos de la versión 3. El curso no está, pero el solo índice nos permite tener una enumeración de cuáles son las novedades.
4.1.1. Procesadores#
Tenemos varias alternativas para ejecutar consultas XQuery:
El programa Xidel, que ya usamos para probar XPath.
BaseX, que introduciremos mejor más adelante y tiene tanto interfaz gráfica como de línea de comandos. Es un programa hecho en Java, así que necesitaremos tener instalada antes la máquina virtual. En las distribuciones basadas en Debian hay paquete disponible con lo que echarlo a andar es trivial.
Visual Studio Code con la extensión XML Tools, que requiere alguna configuración adicional, que se trata en el apéndice enlazado.
Otro aspecto a tener presente al usar los procesadores es que XQuery, al comienzo del código, permite especificar cuál es la versión mínima que permite ejecutar dicho código. Por ejemplo, si usamos algo de lo indicado en Cláusulas adicionales, el código no será compatible con XQuery 1.0. Los procesadores están obligados a leer la declaración y, si no soportan esa versión de XQuery, a abortar la ejecución confesando su incapacidad:
xquery version "1.0";
En ausencia de la declaración, se entenderá que se soporta la versión más baja, esto es, 1.0.
4.1.2. FLWOR básico#
La estructura FLWOR es una estructura iterativa (esto es, un bucle), que en XQuery (ya veremos que la versión 3 añade otras) está constituida por la sucesión de cinco cláusulas:
(FOR | LET)+ - WHERE? - ORDER BY? - RETURN
donde FOR es una cláusula iterativa que asigna a una variable los ítems de una secuencia, LET permite definir variables asignándoles valor, WHERE define una condición para que la iteración del bucle se lleve a cabo, ORDER BY permite ordenar los resultados, y RETURN incluye la expresión que resultará de cada iteración. Hemos expresado también la cardinalidad, de la que se deduce que debe haber siempre al menos una cláusula FOR o LET y una RETURN.
Como las expresiones se construyen para transformar documentos XML se hará referencia a los nodos de un documento, pero nuestros primeros ejemplos los haremos utilizando expresiones XPath ajenas a cualquier nodo:
(: Mi primer código XQuery :)
for $animal in ("perro", "gato")
return
"Mi mascota es un " || $animal || "."
Este código devolverá como resultado
Mi mascota es un perro.
Mi mascota es un gato.
Obsérvese que para construir la secuencia hemos usado una expresión XPath[2] y para expresar cuál debe ser el resultado otra. Además, hemos aprovechado para presentar cómo escribir comentarios dentro del código. Añadamos algunos elementos más a la construcción:
for $animal in ("perro", "gato")
let $como := "bonito"
return
"Mi mascota es un " || $animal || " " || $como || "."
Este código devuelve:
Mi mascota es un perro bonito.
Mi mascota es un gato bonito.
También podemos probar a ordenar los resultados:
for $animal in ("perro", "gato")
let $como := "bonito"
order by $animal
return
"Mi mascota es un " || $animal || " " || $como || "."
lo cual ordenará los resultados según la expresión XPath $animal, o
sea, el valor de esa variable para cada iteración. Como los valores son cadenas
y las cadenas tienen ordenación, es posible hacerlo. Podríamos haber utilizado
cualquier otra expresión que devolviera valores ordenados según los criterios de
XPath como, por ejemplo, fn:string-length($animal).
Por último, podemos añadir también una condición que será una expresión XPath que devuelva un resultado lógico:
for $animal in ("perro", "gato")
let $como := "bonito"
where $animal != "perro"
order by $animal
return
"Mi mascota es un " || $animal || " " || $como || "."
En esta ocasión evitaremos tener como mascota un «perro bonito».
Otro aspecto, especialmente útil cuando generamos una salida de puro texto, es el hecho de que la evaluación de la expresión puede devolver una secuencia[3], en cuyo caso el procesador suele escribir cada ítem de la secuencia en línea aparte. Por ejemplo:
for $animal in ("perro", "gato")
return
("animal:", $animal)
devuelve:
animal:
perro
animal:
gato
Pero también podríamos haber hecho que la propia estructura FOR fuera el
ítem de una secuencia:
(
"Las mascotas de mi casa:",
for $animal in ("perro", "gato")
return
" - Un " || $animal || ".",
"Y no tengo nada más que decir."
)
Esto devolverá el siguiente resultado:
Las mascotas de mi casa:
- Un perro.
- Un gato.
Y no tengo nada más que decir.
Como puede apreciarse la primera y la última frase no forman parte de ninguna estructura iterativa por lo que sólo se escriben una vez.
Prudencia
Aunque vemos una estructura iterativa formalmente parecida a la de la programación estructurada, XQuery no actúa del mismo modo, ya que es un lenguaje funcional. Cuando XQuery evalua secuencias (y una estructura de este tipo consiste en recorrer una secuencia), debe respetar el orden de presentación, lo que quiere decir que lo primero en la entrada será lo primero en la salida (a menos que usemos ORDER para alternar este orden). Por eso:
for $animal in ("perro", "gato")
return
$animal
mostrará primero el perro y luego el gato, o:
(: Suponemos que la entrada es un documento XML :)
for $animal in //animal
return
$animal/@nombre
devuelve los nombres de los animales en el orden en que los elementos animal aparecen en el documento.
Sin embargo, el orden de evaluación está totalmente indefinido y el procesador no tiene por qué evaluar primero la expresión que aparece antes en la secuencia. Dependiendo de qué sea más óptimo, podrá alterar ese orden o evaluarlas en paralelo. Lo expuesto es válido para la evaluación de cualquier secuencia, no sólo de aquellas recorridas por un FOR. Esta expresión:
("perro", "gato")
mostrará primero «perro» y luego «gato», pero no podremos asegurar qué se evaluó antes. Por ahora esto tiene poca importancia, pero la cobrará más adelante.
Analicemos más pormenorizadamente cada parte:
- FOR
La cláusula permite añadir un contador usando la palabra
at. Por ejemplo, el códigofor $animal at $i in ("perro", "gato") return $i || ". Mi mascota es un " || $animal || "."
mostrará:
1. Mi mascota es un perro. 2. Mi mascota es un gato.
Nota
El contador hace referencia al orden del animal en la secuencia, no al orden de las iteraciones. Por ello, el resultado que muestra el gato siempre estará asociado al 2, incluso aunque usando
order byse llegue a mostrar antes.Como deja vislumbrar la cardinalidad antes mostrada, puede haber varios
foren la misma estructura:for $animal in ("perro", "gato") for $dueño in ("Marta", "Francisco") return $dueño || " tiene un " || $animal || "."
El código devuelve:
Marta tiene un perro. Francisco tiene un perro. Marta tiene un gato. Francisco tiene un gato.
Lo anterior también puede ser escrito con un único
for:for $animal in ("perro", "gato"), $dueño in ("Marta", "Francisco") return $dueño || " tiene un " || $animal || "."
- LET
La sintaxis es la misma que para
for: podemos usar varias cláusulas con una definición o poner varias definiciones en una cláusula separándolas con coma.
- WHERE
No tiene especiales dificultades, salvo tener claro que se evalúa usando el valor efectivo booleano de la expresión.
- ORDER BY
La expresión XPath que se evalúa debe devolver un valor para el que haya definida un orden (un número o una cadena, por ejemplo). Los resultados se ordenarán de menor a mayor. Sin embargo, podemos añadir las palabras reservadas
ascending(que no tendrá efecto) odescendingque invertirá la ordenación para que se haga de mayor a menor.
- RETURN
Indica mediante una expresión XPath qué debe devolver cada iteración del bucle. Tenga presente que, si no generamos una salida XML, esta cláusula sólo podrá contener una única XQuery, lo que permite anidar otro estructura FLWOR:
for $animal in ("perro", "gato") return ( "Nombres habituales de " || $animal || " son:", for $nombre in ("misho", "babo") return " - " || $nombre )
El código anterior devuelve la salida:
Nombres habituales de perro son: - misho - babo Nombres habituales de gato son: - misho - babo
4.1.3. Construcción de salida XML#
Hasta ahora, para ilustrar los principios de la estructura FLWOR, estamos generando resultados que son mero texto. Sin embargo, podemos también generar una salida XML y en este caso, el uso y comportamiento de XQuery será ligeramente distinto, ya que:
Cuando la salida es de texto, se evalúa una única expresión XQuery, por lo que la estrategia para lograr evaluar varias es devolver una secuencia, cada uno de cuyos ítems es una expresión XQuery.
Un documento XML está constituido por múltiples nodos (elementos, atributos, etc), el contenido de cada uno de los cuales podrá ser una expresión XQuery. Para generar cada nodo hay dos alternativas: los constructores directos y los constructores computados, que podemos usar a voluntad.
- Constructores directos
Los constructores directos son aquellos que consisten en escribir literalmente la salida XML y hacerle notar al procesador que algo es una expresión XPath a evaluar mediante el uso de corchetes
{}.Por ejemplo:
<mascotas> <!-- Ejemplo de salida XML --> { for $animal at $i in ("perro", "gato") return <animal id="{$i}">{$animal}</animal> } </mascotas>
Sin embargo, cuando la entrada es un documento XML tenemos que tener cuidado, porque las expresiones no siempre devolverán valores atómicos y eso influye en el comportamiento. Por ejemplo, si generamos un XML a partir del ejemplo sobre casilleros usando este código
<lista> <!-- Una lista muy simple --> { for $p in //profesor return <p>{$p/@id}</p> } </lista>
resultará el siguiente XML
<lista> <!-- Una lista muy simple --> <p id="p1"/> <p id="p13"/> <p id="p15"/> <p id="p17"/> <p id="p28"/> <p id="p81"/> <p id="p86"/> </lista>
porque
$p/@ides un nodo atributo, no una cadena. Para que el identificador hubiera pasado a ser el contenido de los elementos p, deberíamos haberlo atomizado expresamente:<lista> <!-- Una lista muy simple --> { for $p in //profesor return <p>{data($p/@id)}</p> } </lista>
Si evaluamos un nodo elemento, nos pasará lo mismo: se escribirá el elemento, no su valor atómico.
- Constructores evaluados
Los constructores evaluados utilizan una sintaxis no XML para expresar la estructura del XML de salida. Son especialmente útiles cuando el nombre del elemento o del atributo son dinámicos y dependen del contenido de la entrada:
element lista { for $p in //profesor return element p {$p/@id} }
Como puede verse, se usa la palabra
elementcon dos argumentos: el nombre del elemento (lista), que es literal y la expresión de su contenido, que, como se obtiene a través de una expresión XPath, hay que encerrar entre llaves. Por supuesto, el primer argumento también podría ser una expresión evaluada:element {name(/*)} { for $p in //profesor return element p {$p/@id} }
De esta forma, el nodo raíz de la salida tendrá el mismo nombre (claustro) que el del documento original. Obsérvese, además, que la evaluación de
$p/@idresulta un nodo atributo, por lo que el elemento p estará vacío y tendrá un atributo que se llama igual que el de profesor y con su mismo valor.Si quisiéramos dotar de más contenido a p, podríamos expresar tal contenido como una secuencia:
element {name(/*)} { for $p in //profesor return element p {($p/@id, $p/nombre)} }
Ahora p, dispondrá de un atributo y de un elemento nombre como contenido. Por supuesto, podemos cambiar los nombres de los atributos o los elementos complicando un poco la expresión. Por ejemplo:
element {name(/*)} { for $p in //profesor return element p {( $p/@id, element nombre_completo {$p/nombre || " " || $p/apellidos} )} }
o lo mismo si queremos mezclar constructores directos y evaluados:
element {name(/*)} { for $p in //profesor return element p {( $p/@id, <nombre_completo>{$p/nombre || " " || $p/apellidos}</nombre_completo> )} }
Sólo hemos ilustrado los constructores evaluados para elementos, pero los hay también para los demás componentes de un XML como atributos (
attribute nombre contenido), comentarios (comment contenido), texto (text contenido) o instrucciones de procesamiento (processing-instruction nombre contenido):let $href := "claustro.xsl" return ( processing-instruction xml-stylesheet {'type="text/xsl" href="' || $href || '"'}, element {name(/*)} { for $p at $i in //profesor return ( comment {"Profesor #" || $i}, element p {( attribute codigo {$p/@id}, $p/nombre )} ) } )
4.1.4. Funciones de usuario#
XQuery permite, antes de la estructura FLWOR, definir funciones de usuario que piensen usarse luego en la estructura. Por ejemplo:
(: función propia :)
declare function local:declara-estilo($href) {
processing-instruction xml-stylesheet {'type="text/xsl" href="' || $href || '"'}
};
(: Como no necesitamos for ni let usamos directamente el contenido de 'return' :)
(
local:declara-estilo("claustro.xsl"),
element {name(/*)} {
for $p at $i in //profesor
return
(
comment {"Profesor #" || $i},
element p {(
attribute codigo {$p/@id},
$p/nombre
)}
)
}
)
4.1.5. Cláusulas adicionales#
XQuery 3 hizo algunos añadidos a la estructura original FLWOR:
(FOR | LET | WINDOW)+ - WHERE? - ORDER BY? - GROUP BY? - COUNT? - RETURN
Prudencia
En realidad, la expresión de arriba es una simplificación que busca
la simetría con la que facilitamos antes y que es la propia de XQuery 1.0.
En la versión 3, las únicas limitaciones a la estructura FLWOR es que debe
empezar por un FOR, un LET o un WINDOW, y que debe rematarse con
el único RETURN posible; entre medias puede haber todas las cláusulas que
queramos (excepto RETURN) en el orden y número que queramos, o sea:
(FOR | LET | WINDOW) - (FOR | LET | WINDOW | WHERE | ORDER BY | GROUP BY | COUNT)* - RETURN
- COUNT
permite definir un contador para las iteraciones:
xquery version "3.0"; for $animal in ("perro", "gato", "jilguero") where $animal != "perro" count $n return $n || ". Mi mascota es un " || $animal || "."
Prudencia
countpuede usarse antes de la sentenciawhere, pero en ese caso también contará las iteraciones filtradas:xquery version "3.0"; (: gato es 2, y jilguero es 3 :) for $animal in ("perro", "gato", "jilguero") count $n where $animal != "perro" return $n || ". Mi mascota es un " || $animal || "."
- GROUP BY
como su homónimo en SQL, permite agrupar los resultados según un determinado criterio. Por ejemplo, esto sacaría un nuevo
casillero.xmlen que los profesores están agrupados por casilleros:xquery version "3.0"; element {name(/*)} { for $p in //profesor let $depart := $p/departamento where $depart group by $depart return <departamento nombre="{$depart}"> {$p} </departamento> }
Y si queremos incluir los sustitutos, podríamos echar mano de XPath 2:
xquery version "3.0"; element {name(/*)} { for $p in //profesor let $depart := if ($p/departamento) then $p/departamento else //profesor[@id = $p/@sustituye]/departamento where $depart group by $depart return <departamento nombre="{$depart}"> {$p} </departamento> }
Nota
Obsérvese que al usar el
FORsin la cláusulaGROUP BYen cada iteración, la variable$pcontiene un elemento profesor. En cambio, cuando se usaGROUP BY,$ppasa a contener una secuencia con todos los elementos profesor de un mismo departamento.- WINDOW
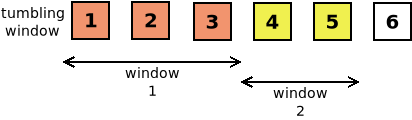
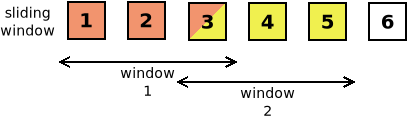
La cláusula (posiblemente la más compleja de las incorporadas) permite agrupar datos al igual que
group by, pero en vez de agrupar por valor, agrupa por secuencias de ítems consecutivos. Por ejemplo, nos permitiría agrupar los tres primeros ítems, luego los tres siguientes, y así sucesivamente en grupos de tres.Cada uno de estos grupos o rangos recibe el nombre de windows y puede haber de dos tipos:
tumbling window, que son rangos que nunca se solapan, esto es, que no comparten ítems, por lo que el ítem que abre una ventana siempre tiene que ser posterior al último que cierra la ventana anterior.
sliding window, que son rangos solapables y, por tanto, dos ventanas consecutivas podrán tener uno o más ítems comunes.
Para definir los límites de la ventana la sintaxis permite definir una condición de comienzo y otra de fin. Por ejemplo:
xquery version "3.0"; for tumbling window $w in (1 to 10) start when true() end at $e when $e mod 3 = 0 return "- " || string-join($w, ",")
establece una condición de comienzo que siempre cumple y una de final en los múltiplos de 3. Como las ventanas no pueden solaparse, lo que significa que la ventana siguiente sólo puede comenzar después de que haya acabado la anterior, el resultado es éste:
- 1,2,3 - 4,5,6 - 7,8,9 - 10
Nota
Percátese de que puede asignar una variable al elemento (inicial o final) de la ventana usando
at, aunque puede hacerse elisión (end $een vez deend at $e).A las condiciones podemos añadirle
onlypara forzar a que se cumpla y, si no es así, que no se llegue a constituir la ventana. Por tanto, el código:xquery version "3.0"; for tumbling window $w in (1 to 10) start when true() only end at $e when $e mod 3 = 0 return "- " || string-join($w, ",")
no llegará a constituir la última ventana anterior, ya que ésta no acababa en un múltiplo de tres:
- 1,2,3 - 4,5,6 - 7,8,9
En cambio, si cambiamos el tipo de ventana…
xquery version "3.0"; for sliding window $w in (1 to 10) start when true() only end at $e when $e mod 3 = 0 return "- " || string-join($w, ",")
…ahora las ventanas se pueden solapar y, como cualquier ítem, es susceptible de ser el comienzo de una el resultado es el siguiente:
- 1,2,3 - 2,3 - 3 - 4,5,6 - 5,6 - 6 - 7,8,9 - 8,9 - 9 - 10
Por último, existe también la posibilidad de asignar una variable al siguiente elemento al que comienza o termina una ventana con la palabra
next:xquery version "3.0"; for tumbling window $w in (1 to 10) start at $i next $i_next when $i_next mod 2 = 0 only end at $e when $e mod 3 = 0 return "- " || string-join($w, ",")
Este código provoca que sólo se tome como comienzo de ventana aquel ítem cuyo siguiente en la secuencia sea múltiplo de dos. Como consecuencia, el resultado es:
- 1,2,3 - 5,6 - 7,8,9
Nota
La variable
$ino la usamos para nada, por lo que podríamos ahorrárnosla:start next $i_next when $i_next mod 2 = 0.
4.1.6. Actualización de datos#
Estrictamente XQuery permite la consulta de datos y la generación de una
salida en forma de nuevo XML. Buscando la analogía con SQL, esto lo hace
equivalente a SELECT que obtiene datos de una base de datos relacional y
genera una salida en forma de tabla. Sin embargo, el DML de SQL lo
componen, además de SELECT, INSERT, UPDATE y DELETE, los cuales
permiten alterar el contenido. Para dotar a XQuery de la capacidad de
modificación que confieran estas tres sentencias, el W3C definió como
extensión al lenguaje (XQuery Update Facility 3.0) cuatro nuevas expresiones que puede
incluirse en la cláusula RETURN para modificar la fuente
original, en vez de generar una salida:
insert, que permite añadir nodos.
delete, que permite borrar nodos.
replace, que permite reemplazar nodos.
rename, que permite renombrar nodos.
Advertencia
Cuando se hacen modificaciones, es imprescindible tener presente
que XQuery no asegura el orden de evaluación de las secuencias. Por tanto, si tenemos dos expresiones que modifican los
datos de entrada (expr1 y expr2) y se escriben así:
(
expr1,
expr2
)
la evaluación de la segunda expresión no debería depender de que la
evaluación de la primera se hubiera completado. Si así fuera, deberíamos
reescribir el código para asegurarnos que la evaluación de expr2 se
hará en segundo lugar.
4.1.6.1. Modificación#
Prudencia
Estas sentencias de actualización de la fuente tienen sentido cuando el origen XML se utiliza como una base de datos, no como un archivo independiente, por lo que es más pertinente practicarlas en la próxima unidad dedicada al almacenamiento y, en particular, en la parte dedicada a bases nativas. Se incluye aquí su explicación para no desgajarla del resto del lenguaje XQuery.
insertPodemos insertar tanto elementos como atributos y especificando exactamente dónde. Por ejemplo, la expresión:
insert node <foo/> into //profesor[1]
Añade un elemento foo al final del primer profesor. Variantes a esto podrían haber sido:
insert node <foo/> as last into //profesor[1]
o, si lo queremos añadir al comienzo del elemento:
insert node <foo/> as first into //profesor[1]
Para agregarlo en algún punto intermedio, tendríamos que echar mano de
beforeoafter:insert node <foo/> after //profesor[1]/nombre
Obsérvese que estamos agregando un nodo y, en consecuencia, el destino debe ser único y no varios, ya que un nodo sólo puede añadirse en un lugar. Si quisiéramos agregar un nodo foo a cada profesor, entonces tendríamos que echar mano de la estructura FLWOR explícita:
for $p at $n in //profesor return insert node <foo>{$n}</foo> after //profesor[1]/nombre
Hemos complicado un poco la inserción para que se vea que estamos usando un constructor directo para el elemento foo. De hecho, también podríamos haber usado un constructor evaluado:
for $p at $n in //profesor return insert node element foo {$n} after $p/nombre
En realidad, es posible insertar una secuencia de nodos:
insert node (<foo/>, <bar/>) into //profesor[1]
Y también atributos, aunque usando un constructor evaluado:
insert node attribute foo {"bar"} into //profesor[1]
deleteBorra la secuencia de nodos que se exprese como argumento. Por ejemplo, la siguiente expresión elimina el atributo casillero de todos los profesores que lo tengan.
delete node //profesor/@casillero
replaceReemplaza el nodo indicado por otro que se le facilite:
replace node //profesor[1]/apelativo with <apelativo>Joselito</apelativo>
Aunque en este caso, como nuestra intención era cambiar el contenido y no el nombre del nodo, quizás habría sido mejor:
replace node //profesor[1]/apelativo/text() with "Josélito"
Por supuesto, también podemos cambiar atributos:
replace node //profesor[1]/@id with attribute id {"p22"}
Cuando lo que se quiere es reemplazar no el nodo completo, sino su valor (que es lo que hemos pretendido en los dos ejemplos anteriores, puede usarse la expresión
replace value of nodeen vez dereplace node:replace value of node //profesor[1]/apelativo with "Joselito"
y también:
replace value of node //profesor[1]/@id with "p22"
Prudencia
Si la expresión no es un literal, como es el caso, sino una expresión que debe evaluarse, entonces tiene que escribirse
text {expr}:replace value of node //profesor[1]/@id with text {fn:generate-id()}
renamereplacesustituye por completo el nodo, lo cual incluye todos sus descendientes.rename, en cambio, nos permite cambiar el nombre del nodo sin alterar en absoluto su contenido:rename node //profesor[1]/apelativo as "apodo"
Y, de nuevo, también permite cambiar el nombre de un atributo:
rename node //profesor[1]/@id as "codigo"
4.1.6.2. Modificación en memoria#
Los ejemplos anteriores sirven todos para modificar el documento original. Ahora bien, supongamos que queremos generar una salida que es muy parecida al archivo original. Con las técnicas vistas antes de este epígrafe de actualización, esa generación a pesar de ser una pequeña variante del original, nos supondría bastante esfuerzo. Por ese motivo, XQuery permite la posibilidad de copiar parte del documento original en memoria, hacer los cambios usando las técnicas arriba vistas y, finalmente, volcar en la salida la copia.
Por ejemplo, imaginemos que quisiéramos generar una salida del documento de casilleros exactamente igual al original con la única diferencia de que el elemento casillero pasa a ser un atributo. El ejercicio podríamos realizarlo así:
xquery version "3.0";
copy $claustro := //claustro
modify (
for $p in $claustro/profesor
return (
insert node attribute departamento {$p/departamento} into $p,
delete node $p/departamento
)
)
return
$claustro
Esto es:
Hacemos una copia del elemento raíz (claustro) con
copy.Realizamos las modificaciones precisa dentro de
modifyDevolvemos con
returnla copia modificada.
Para no enmarañar el ejemplo, hemos evitado tener en cuenta que hay profesores sin departamento a los que, por tanto, no hay que hacerle ninguna modificación. Esto, no obstante, no es algo que no podamos resolver con if:
xquery version "3.0";
copy $claustro := //claustro
modify (
for $p in $claustro/profesor
return (
if ($p/departamento) then (
insert node attribute departamento {$p/departamento} into $p,
delete node $p/departamento
)
else ( (: No hay modificación alguna :) )
)
)
return
$claustro
4.1.7. Ejercicios resueltos#
Para ilustrar el uso de XQuery tomemos el primer ejercicio XML resuelto sobre recetas:
<?xml version="1.0" encoding="UTF-8"?>
<recetas>
<!-- El tiempo está en minutos -->
<receta id="r01" nombre="ensalada" preparacion="5">
<ingrediente nombre="tomate" unidad="pieza" cantidad="2" />
<ingrediente nombre="cebolla" unidad="pieza" cantidad=".25" />
<ingrediente nombre="lechuga" unidad="gramo" cantidad="150" />
<ingrediente nombre="sal" unidad="gramo" cantidad="2" />
<ingrediente nombre="vinagre" unidad="cc" cantidad="3" />
<ingrediente nombre="aceite" unidad="cc" cantidad="6" />
</receta>
<receta id="r02" nombre="bocadillo de anchoas" preparacion="4">
<ingrediente nombre="pan" unidad="pieza" cantidad="1" />
<ingrediente nombre="anchoa" unidad="pieza" cantidad="3" />
</receta>
<!-- Más recetas -->
</recetas>
Obtener un listado de texto ordenado alfabéticamente con las recetas de más de tres ingredientes:
Recetas de cocina: 1. ensalada (5 minutos) * tomate (2 pieza) * cebolla (.25 pieza) * lechuga (150 gramo) * sal (2 gramo) * vinagre (3 cc) * aceite (6 cc) 2. etc...Este listado se puede obtener con el siguiente código:
XQuery propuesto#( "Recetas de cocina:", for $receta in //receta (: Sólo mostramos las recetas complicadas: +3 ingredietes :) where count($receta/ingrediente) > 3 order by $receta/@nombre count $num return ( " " || $num || ". " || $receta/@nombre || " (" || $receta/@preparacion || " minutos)", for $ingrediente in $receta/ingrediente return " * " || $ingrediente/@nombre || " (" || $ingrediente/@cantidad || " " || $ingrediente/@unidad || ")" ) )
Generar otro XML idéntico en que los atributos nombre y cantidad de cada ingrediente se conviertan en nodos elemento:
XQuery propuesto#element {fn:local-name(/*)} {( /*/@*, for $receta in //receta return element receta { $receta/@*, for $ingrediente in $receta/ingrediente return (: En vez de reconstruir de 0 un elemento ingrediente tomamos una copia e insertamos y eliminamos :) copy $i := $ingrediente modify ( insert node element nombre {data($i/@nombre)} into $i, insert node element cantidad {data($i/@cantidad)} into $i, delete node $i/@nombre, delete node $i/@cantidad ) return $i } )}
4.2. XSLT#
Un estudio consistente de este lenguaje de transformación es demasiado amplio para la escasa carga lectiva del módulo, pero pertinente a la vista del currículo. Por ello, trasladamos su desarrollo al apéndice correspondiente.
4.3. Ejercicios propuestos#
Nota
Para no despojar de interés práctico la unidad dedicada al almacenamiento, puede ahora centrarse en resolver los ejercicios cuya salida en texto y no XML, ya que estos últimos, por centrarse en obtener variaciones del documento original, están pensados para resolverse utilizando las técnicas de actualización.
A partir del XML sobre facturas obtenga una lista de clientes en que se exprese para cada uno de ellos su nombre y la cantidad de facturas emitidas a su nombre. Por ejemplo:
Clientes del negocio: - Perico de los Palotes: 3 factura(s). - Mariquilla de la O: 2 factura(s).
A partir del XML sobre facturas obtenga un listado de facturas en que se expresa de cada una de ellas el código y el nombre del cliente al que se facturó. Por ejemplo:
Listado de facturas: - f01: Perico de los Palotes - f02: Mariquilla de la O
A partir del XML sobre facturas, obtenga un listado de facturas como el descrito en el ejercicio 15 de XSLT.
A partir del XML sobre facturas, obtenga un listado de facturas en que se exprese de cada una de ellas el código y el coste total. Por ejemplo:
Coste de las facturas: - f01: 1.7€ - f02: 5.2€
Solución propuesta 2(usando XPath 1.0).Tome el XML sobre facturas y componga otro similar en que las facturas, en vez de estar aparte, sean hijas del cliente a nombre del que se han emitido.
Solución propuesta 1(sin modificaciones en memoria).Solución propuesta 2(con modificaciones en memoria).A partir del XML sobre préstamos en una biblioteca, obtenga un listado de libros ordenados por año de publicación, en que se incluya el nombre y el número total de ejemplares. Por ejemplo:
Libros en la biblioteca: - Don Quijote de la Mancha: 5 ejemplar(es). - Las aventuras del bachiller Trapaza: 3 ejemplar(es).
A partir del XML sobre préstamos en una biblioteca, obtenga un listado de socios con el número de préstamos que han solicitado. Por ejemplo:
Listado de socios: - Perico de los Palotes: 5 préstamo(s). - Mariquilla de la O: 2 préstamo(s). - Ana al-Fabeta: 0 préstamo(s).
Como el ejercicio anterior, pero sin que aparezcan los socios que no han pedido ningún préstamo. Por tanto, en el ejemplo anterior, no aparecería el último socio.
Tome el XML de préstamos en una biblioteca y componga otro en que los préstamos hechos por un lector, en vez de aparte como en el original, aparezcan como elementos hijo de dicho lector.
A partir del XML sobre ventas de coches, haga un listado de modelos de coches con la expresión de los coches totales de los que hay de cada uno. Por ejemplo:
Modelos disponibles: - León: 5 coches. - Ibiza: 6 coches.
Haga un listado como el del ejercicio anterior, pero sólo cuente los coches que no han sido reservados.
A partir del XML sobre ventas de coches, haga un listado de clientes que incluya su nombre y la cantidad de coches que ha reservado. Por ejemplo:
Listado de clientes: - Perico de los Palotes: 2 coche(s). - Mariquilla de la O: 1 coche(s).
Tome el XML de venta de coches y componga otro similar en que los coches sean elementos hijo del modelo correspondiente.
A partir del XML sobre figuras 2D, haga un listado de figuras como en el que se pide para el ejercicio 1 de XSLT
A partir del XML sobre figuras 2D, haga un listado de figuras como en el que se pide para el ejercicio 3 de XSLT
A partir del XML sobre figuras 2D, haga un listado de figuras como en el que se pide para el ejercicio 5 de XSLT
Nota al pie